Comparaison de corpus
Afin de caractériser le corpus Daft, et indirectement de valider l'hypothèse émise au sujet de sa spécificité, nous l'avons comparé au niveau des actes de dialogue
à des corpus similaires de requêtes orientées tâche. Nous avons utilisés trois autres corpus pour cette étude comparative :
- le corpus Switchboard: 200 000 énoncés annotés issus de conversations téléphoniques orientées tâche,
- le corpus MapTask: 128 dialogues dans lesquels une personne devait dessiner une carte en suivant les instructions fournies par une autre,
- le corpus Bugzilla: 1 200 000 commentaires issus de 128 000 rapports d'erreur générés lors du développement de la suite logicielle de la fondation Mozilla.
Nous avons utilisé comme référence la taxinomie classique des actes de dialogue définie par Searle, en convertissant dans celle-ci les taxinomies originellement employées
afin de pouvoir comparer leur distribution:
Malgré la difficulté rencontrée pour la conversion de certains actes (ce qui explique l'existence d'une catégorie "inconnu" supplémentaire),
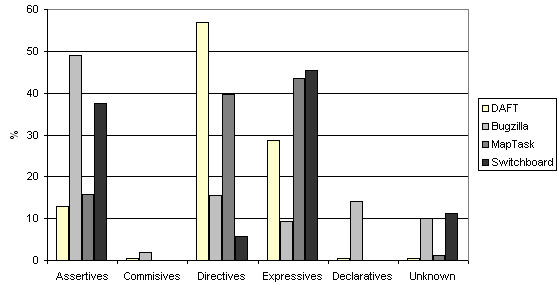
le corpus Daft présente de nettes différences par rapport aux autres. On peut en particulier remarquer :
- Une majorité de directifs (57%), qui s'explique par la forte proportion d'ordres et de questions. Ce phénomène est lié au fait que les utilisateurs semblent
plus directs lorsqu'ils s'adressent à un ordinateur que lorsqu'ils traitent avec d'autres humains (comme c'est le cas dans les trois autres corpus).
- Une proportion assez faible d'assertifs (13%), les utilisateurs semblant préférer exprimer leur ressenti et leur état d'esprit (29%)
plutôt que des faits neutres et objectifs.
- Très peu de promissifs (1%), ce qui s'explique par la nature de la relation utilisateur-agent, dans laquelle ce dernier est clairement subordonné au premier.
Activités conversationnelles du corpus Daft
Au cours de la phase de collecte du corpus, les sujets humains étaient informés qu'ils devaient accomplir un certain nombre de tâches pour lesquelles ils pouvaient
demander de l'aide (si nécessaire) à un agent assistant artificiel. Ils étaient cependant entièrement libres de leurs actions, et pouvaient en particulier saisir des
requêtes formulées comme ils le souhaitaient sans aucune contrainte. Différents comportements ont pu être observés, certains utilisateurs finissant par abandonner
complètement la tâche à accomplir, et le corpus recueilli reflète cette diversité.
Après avoir extrait aléatoirement des phrases du corpus de manière à former deux sous-ensembles représentant un dixième de la taille du corpus chacun, nous avons
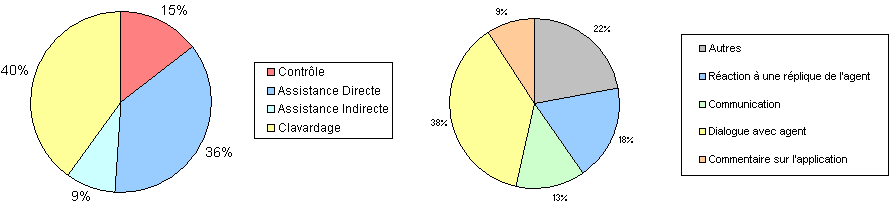
manuellement regroupé les activités similaires, ce qui nous a permis de distinguer finalement quatre activités conversationnelles principales :
- Le contrôle : commandes directe visant à faire interagir l'agent avec l'application directement par lui-même.
- L'assistance directe : requêtes d'assistance explicites, exprimées en tant que telles par l'utilisateur.
- L'assistance indirecte : jugement de l'utilisateur au sujet de l'application ou de l'agent, révélant en fait un besoin d'assistance.
- Le clavardage : où l'utilisateur s'intéresse plus à l'agent qu'à l'application, et qui peut se subdiviser en :
- réaction à une réponse de l'agent : ensemble de façons de manifester son accord/désaccord, son incrédulité ("j'en doute"), son manque de compréhension
("je ne te suis pas") ou son insistance ("s'il te plait réponds").
- fonctions communicatives : formulations d'usage pour initier/achever une conversation, ainsi que les phatiques ("es-tu là ?").
- dialogue avec l'agent : des ordres ("tais-toi") aux questions ("as-tu une âme ?"), et des menaces ("ne me force pas à te tuer !") aux compliments ("tu es jolie").
- commentaires au sujet de l'application: sans la moindre valeur de demande d'assistance ("cette page est belle").
- autres : "Je suis un utilisateur ordinaire", "Je veux faire un don cognitif"...
L'existence même des sous-corpus de clavardage et de contrôle révèlent que les utilisateurs attendent de l'agent qu'il soit capable non seulement de leur fournir
une assistance, mais aussi d'interagir avec l'application par lui-même (et pour eux) et de réagir à des commentaires pas uniquement liés aux tâches qu'ils doivent
assister (phénomène certainement renforcé par la présence visible d'un agent animé).