Corpora comparison
In order to characterize the Daft corpus, and indirectly to validate its specifity, it has been compared to similar task
oriented ones, from a speech acts point of view. We used three other corpora for this comparative study:
- the Switchboard corpus: 200.000 manually annotated utterances from task-oriented phone talks,
- the MapTask corpus: 128 dialogues in which one person has to draw a map following another person instructions,
- the Bugzilla corpus: 1.200.000 comments from 128.000 bug reports created during the development of the Mozilla
Foundation’s suite.
We used the Searle classical taxonomy of speech acts as the reference, converting the original corpora taxonomies into to
this one to be able to compare their repartition:
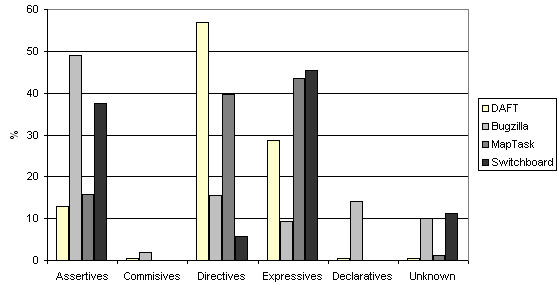
Despite the difficulty to convert some acts (which explains the "unknown" additional category), the Daft corpus clearly appears
as different from the other ones. We can especially note:
- A majority of directives (57%), explained by the high number of orders and questions. This phenomenon can be explained
by the fact users are more direct when interacting with computer than with other humans (as it’s the case for the 3 other
corpora).
- A rather low proportion of assertives (13%), as users seem to prefer to express their feelings and states of mind (29%)
rather than more objective and neutral facts.
- Very few commissives (1%), which is explainable by the nature of the user-agent relationship, where the latter is
subordinate to the former.
Conversational activities of the Daft corpus
During the corpus collection phase, human subjects were informed they had some tasks to do for which they could ask some
help (if needed) from an artificial assistant agent. However, they were completely free to do what they wanted, and particularly
could type whatever they wanted without any constraint. Various behaviors were observed, some users ending up abandoning
their original task, and hence the collected corpus reflects this diversity.
After having randomly extracted two independent subsets of one tenth of the corpus size, we manually gathered requests by
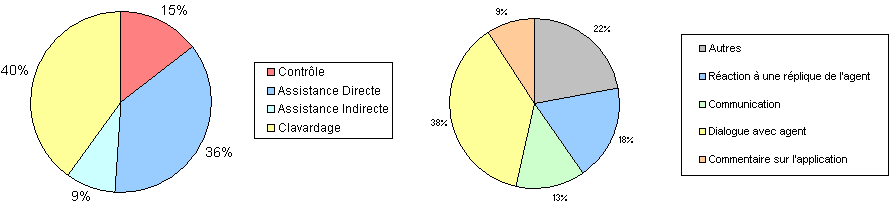
similar activities, which allowed us to distinguish four main conversational activities:
- Control activity: direct controls to make the agent interact directly with the application software by himself.
- Direct assistance activity: explicit help requests from the user.
- Indirect assistance activity: user’s judgments about the software/agent, revealing an actual need of assistance.
- Chat activity: where the user generally focuses more on the agent than the application itself, and which can
itself be divided into:
- reactions to an agent’s answer: a set of way to agree/disagree, expressions of incredulity (“doubt it”), lack of understanding (“you lost me”) or insistence (“please answer”).
- communicative functions: forms used to start/end the communication, as well as some phatic acts (“are you there?”).
- dialogue with the agent: from orders (“shut up”) to questions (“do you have a soul?”) and from threats (“don’t force me to kill you!”) to compliments (“you look cute”).
- comments on the application: without any assistance value (“this page is nice”).
- others : “I’m an ordinary user”, “I want to do a cognitive gift”...
The existence of chat and control subcorpora reveals that users actually expect the agent to be able not only to bring them
assistance, but also to do things in the application by himself (and for them) as well as to have capacities to react to
comment not related to the global task they are working on (phenomenon certainly reinforced by the use of a visible embodied
agent).